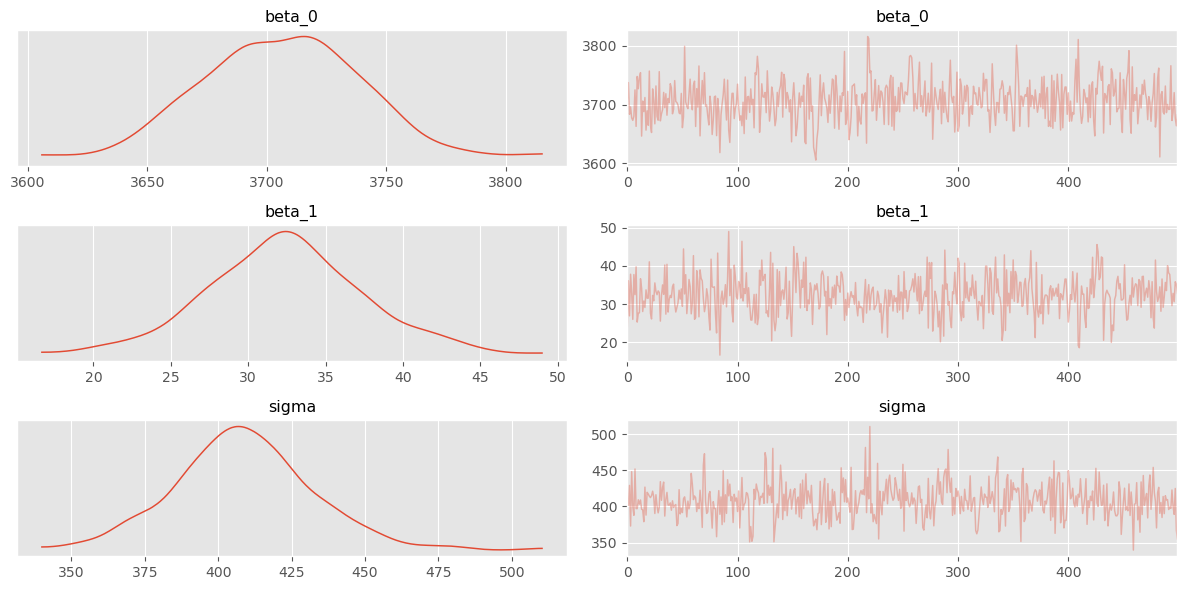
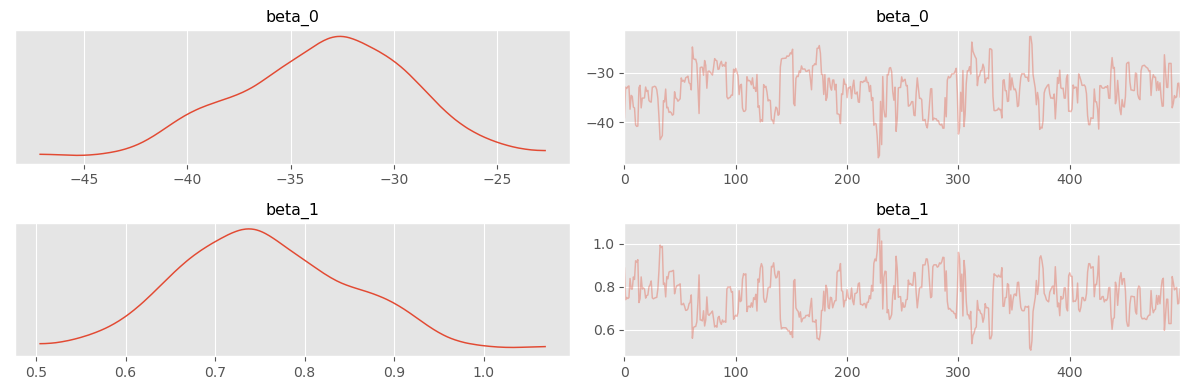
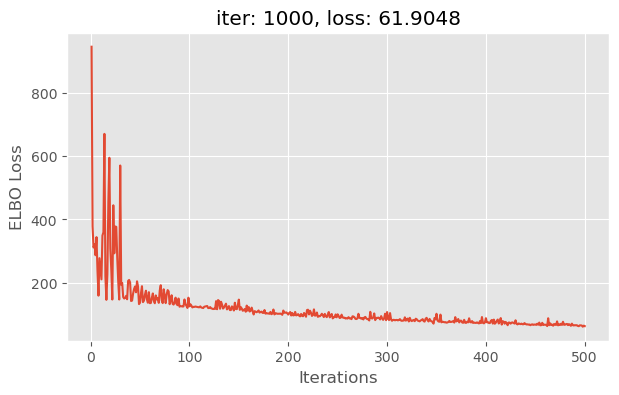
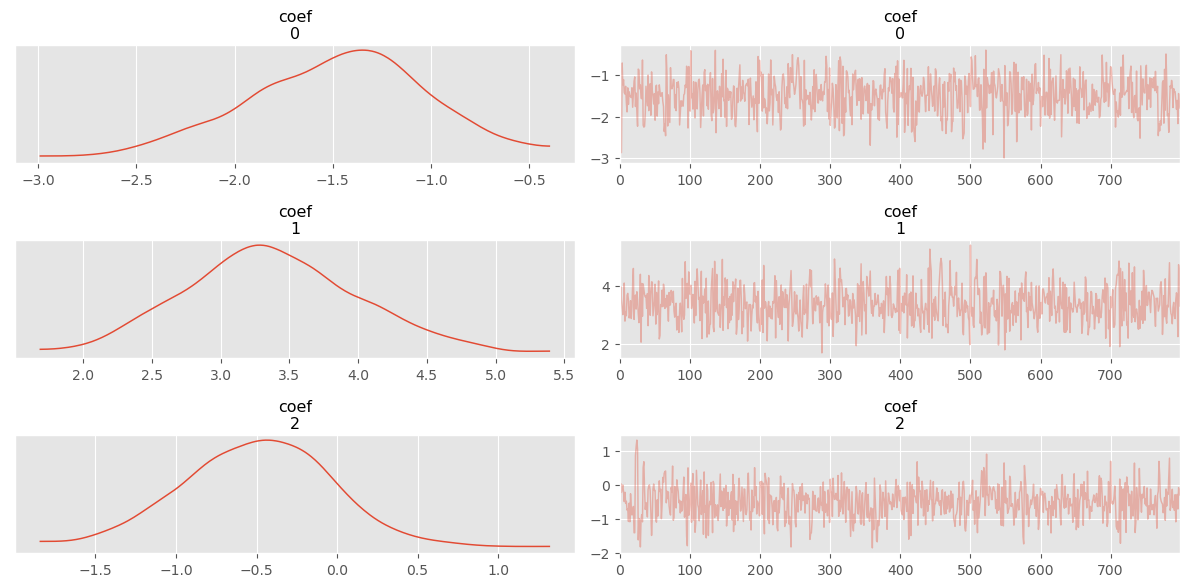
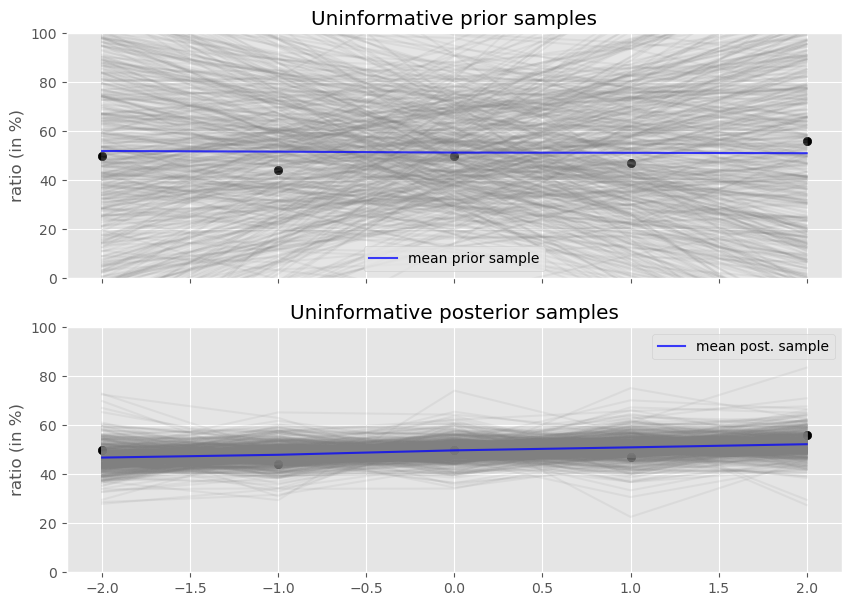
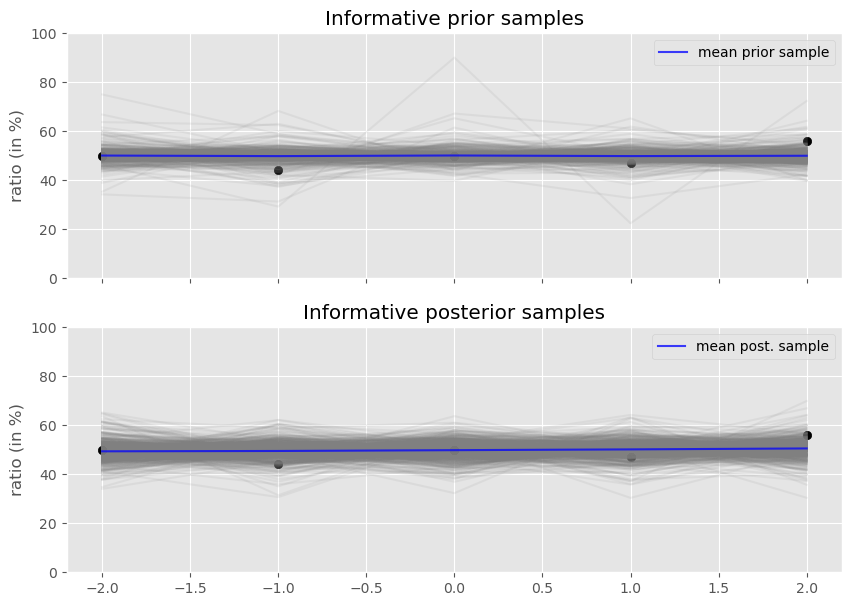
NOT WORKING: I believe it has to do with the autoguide. Solution could be to implement the guide by hand
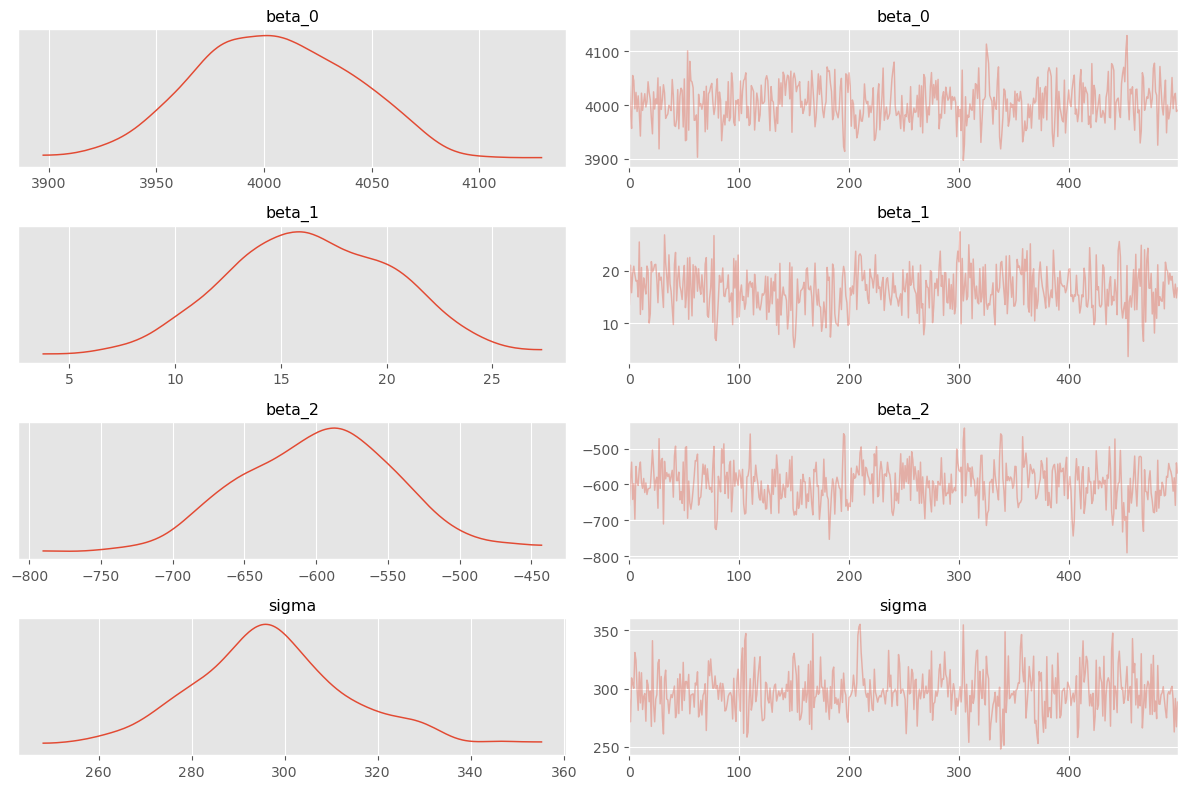
pyro.get_param_store() is comprised of learned parameters that will be used in the Predictive stage. Instead of providing samples, the guide parameter is used to construct the posterior predictive distribution
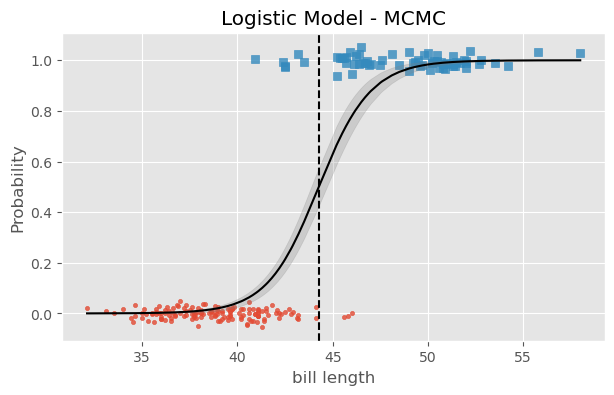
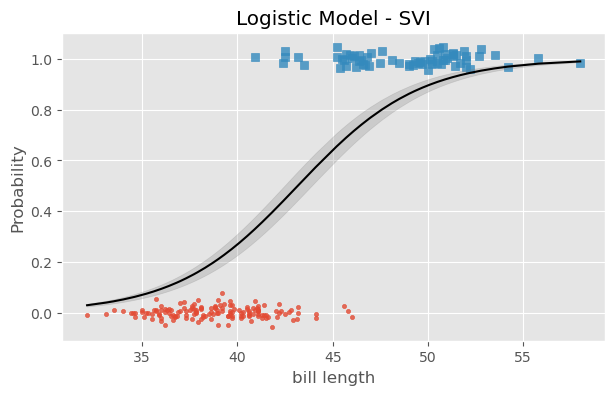
for i, (label, marker) inenumerate(zip(species.categories, (".", "s"))): _filter = (species.codes == i) ## size x = bill_length_obs[_filter] ## x_obs y = np.random.normal(i, 0.02, size=_filter.sum()) ## add small amount of noise for plotting plt.scatter(bill_length_obs[_filter], y, marker=marker, label=label, alpha=.8)plt.plot(predictions['bill_length'], predictions['prob_mu'], color='black')plt.fill_between( predictions['bill_length'], predictions['high'], predictions['low'], alpha=0.25, color='grey')# plt.axvline(# x=predictive_samples['db'].numpy().mean(), linestyle='--', color='black')plt.xlabel('bill length')plt.ylabel('Probability')plt.title('Logistic Model - SVI');
Code 3.24
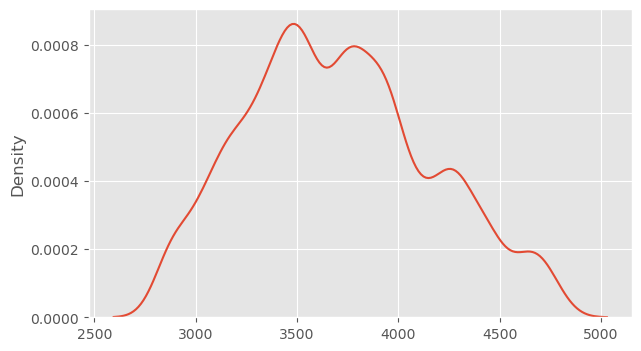
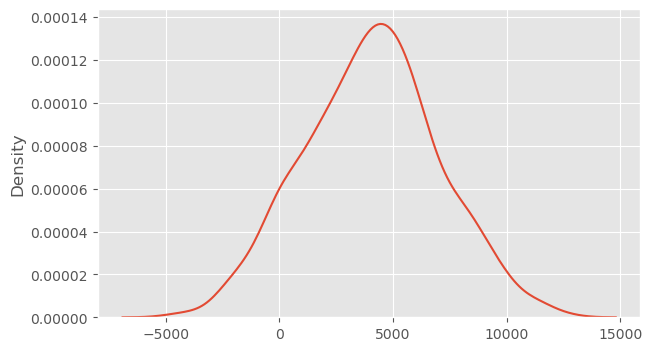
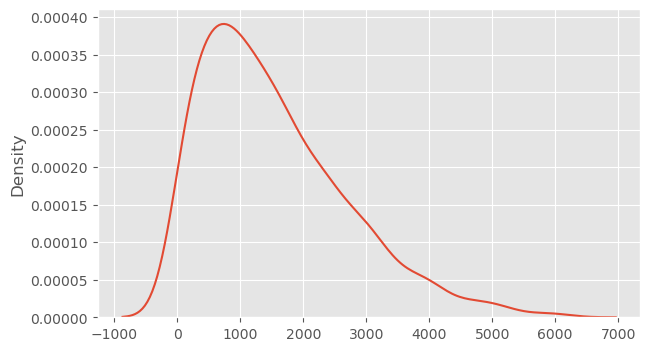
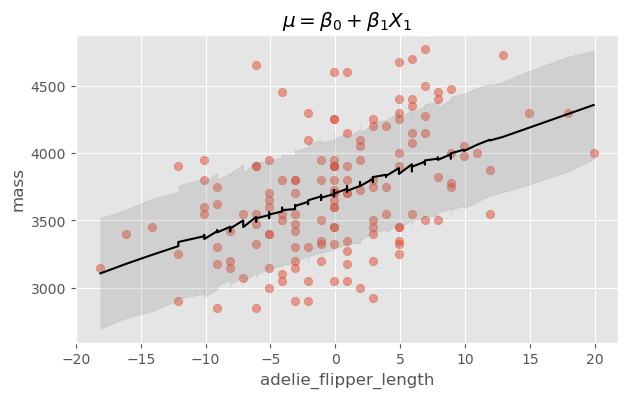
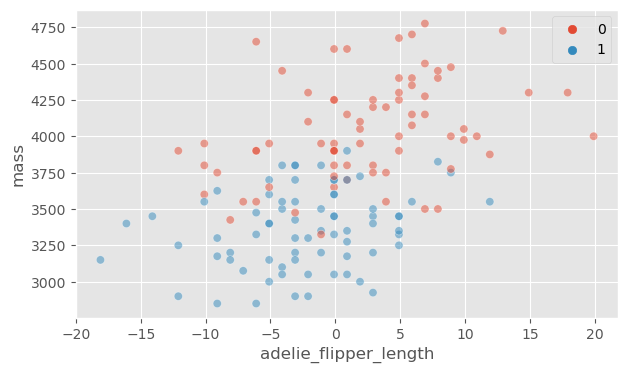
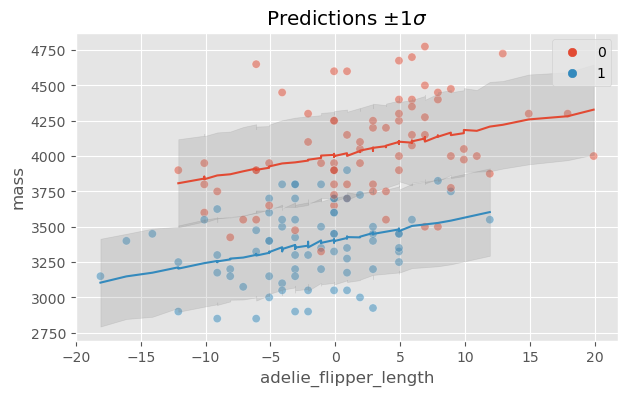
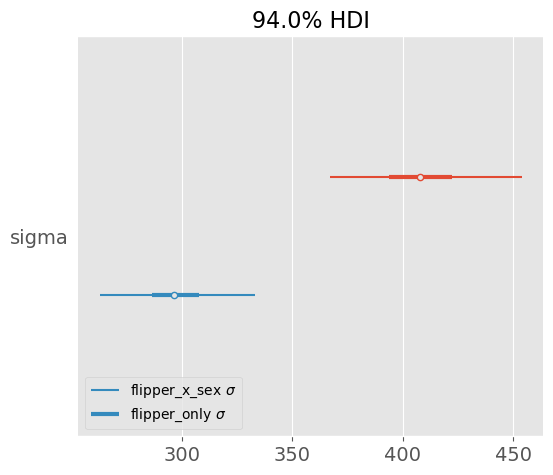
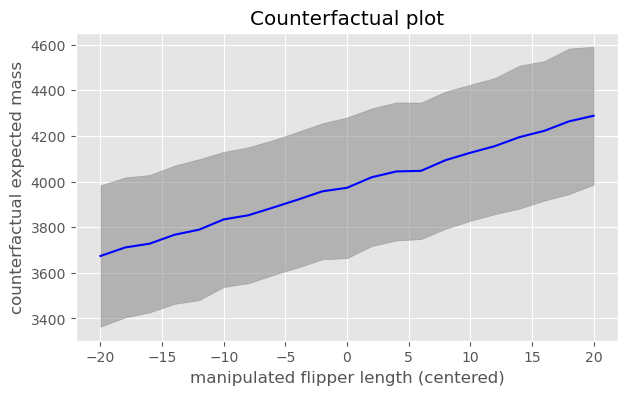
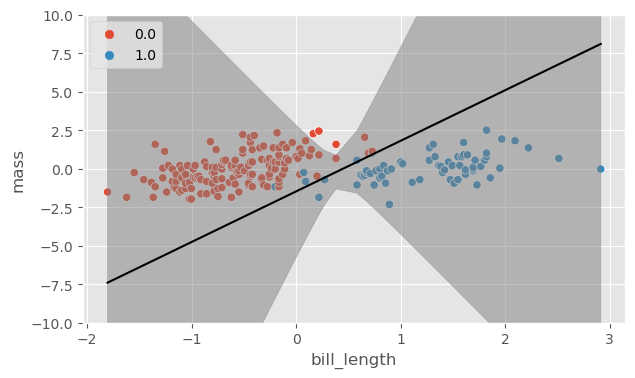
Using body mass and flipper length as covariates
When creating a multidimensional distribution in pyro, there is the added functionality of .to_event(1). This method implies that “these dimensions should be treated as a single event”. - see discussion here