In the probabilistic approach to machine learning, all unknown quantities—predictions about the future, hidden states of a system, or parameters of a model—are treated as random variables, and endowed with probability distributions. The process of inference corresponds to computing the posterior distribution over these quantities, conditioning on whatever data is available. Given that the posterior is a probability distribution, we can draw samples from it. The samples in this case are parameter values. The Bayesian formalism treats parameter distributions as the degrees of relative plausibility, i.e., if this parameter is chosen, how likely is the data to have arisen? We use Bayes’ rule for this process of inference. Let \(h\) represent the uknown variables and \(D\) the known variables, i.e., the data. Given a likelihood \(p(D|h)\) and a prior \(p(h)\), we can compute the posterior \(p(h|D)\) using Bayes’ rule:
\[p(h|D) = \frac{p(D|h)p(h)}{p(D)}\]
The main problem is the \(p(D)\) in the demoninator. \(p(D)\) is a normalization constant and ensures the probability distribution sums to 1. When the number of unknown variables \(h\) is large, computing \(p(D)\) requires a high dimensional integral of the form:
\[p(D) = \int p(D|h)p(h)dh\]
The integral is needed to convert the unnormalized joint probability of some parameter value \(p(h, D)\) to a normalized probability \(p(h|D)\). This also allows us to take into account all the other plausible values of \(h\) that could have generated the data. There are three ways for computing the posterior:
Analytical Solution
Grid Approximation
Approximate Inference
Many problems are complex and require a model where computing the posterior distribution using a grid of parameters or in exact mathematical form is not feasible (or possible). Therefore, you adopt the approximate inference / sampling approach. The sampling approach has a major benefit. Working with samples transforms a problem in calculus \(\rightarrow\) into a problem of data summary \(\rightarrow\) into a frequency format problem. An integral in a typical Bayesian context is just the total probability in some interval. Once you have samples from the probability distribution, it’s just a matter of counting values in the interval. Therefore, once you fit a model to the data using some sampling algorithm, then interpreting the model is a matter of interpreting the frequency of parameter samples (though this is easier said than done).
To gain a better conceptual understanding of algorithmic techniques for computing (approximate) posteriors, I will be diving deeper into the main inference algorithms over the next couple of posts.
Monte Carlo Approximation
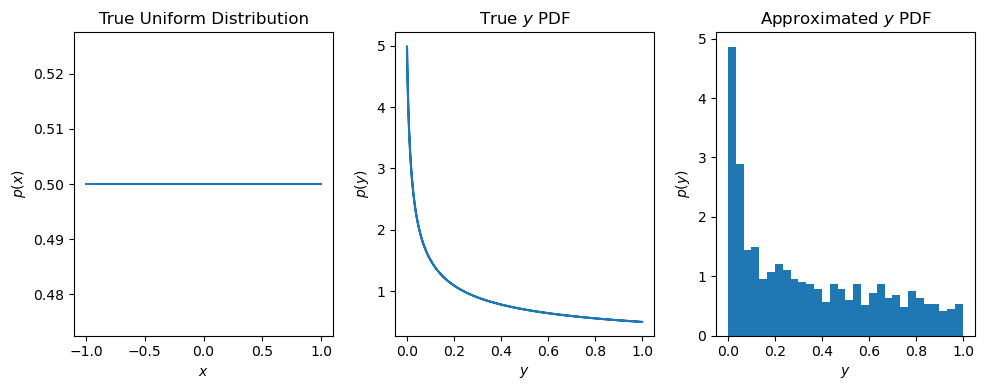
As discussed above, it is often difficult to compute the posterior distribution analytically. In this example, suppose \(x\) is a random variable, and \(y = f(x)\) is some function of \(x\). Here, \(y\) is our target distribution (think the posterior). Instead of computing \(p(y)\) analytically, it is possible to draw a large number of samples from \(p(x)\), and then use these samples to approximate \(p(y)\).
If \(x\) is distributed uniformly in an interval between \(-1, 1\) and \(y = f(x) = x^2\), we can approximate \(p(y)\) by drawing samples from \(p(x)\). By using a large number of samples, a good approximation can be computed.