Metropolis-Hastings (MH) is one of the simplest kinds of MCMC algorithms. The idea with MH is that at each step, we propose to move from the current state \(x\) to a new state \(x'\) with probability \(q(x'|x)\), where \(q\) is the proposal distribution. The user is free to choose the proposal distribution and the choice of the proposal is dependent on the form of the target distribution. Once a proposal has been made to move to \(x'\), we then decide whether to accept or reject the proposal according to some rule. If the proposal is accepted, the new state is \(x'\), else the new state is the same as the current state \(x\).
Proposals can be symmetric and asymmetric. In the case of symmetric proposals \(q(x'|x) = q(x|x')\), the acceptance probability is given by the rule:
\[A = min(1, \frac{p^*(x')}{p^*(x)})\]
The fraction is a ratio between the probabilities of the proposed state \(x'\) and current state \(x\). If \(x'\) is more probable than \(x\), the ratio is \(> 1\), and we move to the proposed state. However, if \(x'\) is less probable, we may still move there, depending on the relative probabilities. If the relative probabilities are similar, we may code exploration into the algorithm such that they go in the opposite direction. This helps with the greediness of the original algorithm—only moving to more probable states.
The Algorithm
Initialize \(x^0\)
for \(s = 0, 1, 2, 3, ...\) do:
Define \(x = x^s\)
Sample \(x' \sim q(x'|x)\) where \(q\) is the user’s proposal distribution
Set new sample to: \(x^{s+1} =
\left\{
\begin{array}{ll}
x' & \quad \text{if} \quad u \leq A(\text{accept}) \\
x & \quad \text{if} \quad x > A(\text{reject}) \\
\end{array}
\right.\)
Random Walk Metropolis-Hastings
The random walk metropolis-hastings (RWMH) corresponds to MH with a Gaussian propsal distribution of the form:
\[q(x'|x) = \mathcal{N}(x'|x, \tau^2 I)\]
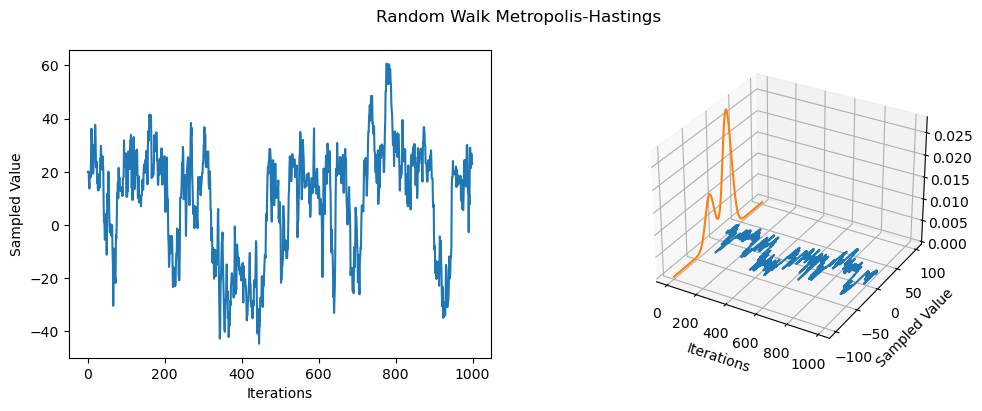
Below, I implement the RWMH for sampling from a 1-dimenensional mixture of Gaussians (implemented using the MixtureSameFamily PyTorch class) with the following parameters:
The mixture distribution can be tricky to sample from as it is has more than one model, i.e., it is a bimodal distribution. However, we can see that the RWMH spends time sampling from both component distributions, albeit, the distribution with the higher probability more. Due to the random search based perturbations (random walk), the sampler seems to randomly jump from component to component, showing that the chain is not sticky. Additionally, the acceptance rate is \(0.803\) indicating that about \(80\%\) of new proposals were accepted.