In optimization, it is often the goal that we need to optimize an objective function while satisfying some constraints. For example, we may want to minimize the scrap rate by finding the optimal process parameters of an manufacturing machine. However, we know the scrap rate cannot be below 0. In another setting, we may want to maximize the throughput of a machine, but we know that the throughput cannot exceed the maximum belt speed of the machine. Thus, we need to find regions in the search space that both yield high objective values and satisfy these constraints. In this blog, we will focus on inequality outcome constraints. That is, the domain of the objective function is
\[\text{lower} \le f(x) \le \text{upper}\]
where \(\text{lower}\) and \(\text{upper}\) are the lower and upper bounds of the objective function. You need not both bounds, but rather one or the other. The set of points \(x'\) that satisfy the constraint are called feasible points and the set of points that do not satisfy the constraint are called infeasible points. Often, in tutorials and or books teaching Bayesian optimization, it is assumed we know a cost function a priori that restricts the outcome space in some way, and then an additional model is used to model the constraint. However, in practice, we often only know a lower and or upper bound according to technical specifications. These bounds do not require an additional model.
In this blog, it will be shown how to use BoTorch to optimize a one-dimensional function with an outcome constraint without using an additional model for the cost (constraint) function. The remainder of the post assumes the reader is already familiar with Bayesian optimization.
Probability of feasibility
In BoTorch it is common to use a Gaussian Process (GP) to model the objective function. The output of the GP is a Gaussian distribution over the predicted values for a given set of input points. It provides not just a single point estimate but a probabilistic prediction that accounts for uncertainty in the predictions. Thus, for each point in the search space, we have a corresponding Gaussian distribution representing the belief of the objective value at that point.
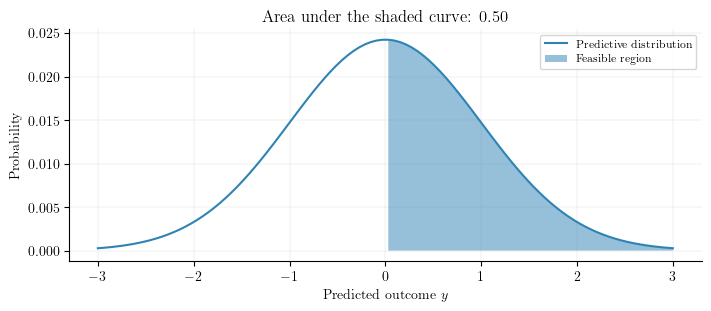
Intuitively, if we have defined an outcome constraint, we can compute the probability that \(f(x)\) is feasible by taking the cumulative distribution function (CDF) of the predictive distribution and computing the area between the lower bound and the upper bound. For example, imagine a GP has made a prediction given an input \(x\). This predictive distribution of the outcome \(y\) is shown below. The prediction is normally distributed around \(0.0\) with plausible predictions ranging from \(-3\) to \(3\). Additionally, there is an outcome constraint of the form
\[0 < f(x)\]
The probability that the prediction is feasible (above \(0\)) is computed using the CDF of the predictive distribution. In this example, the probability of feasibility is \(0.5\). As will be shown below, this probability can then multiplied by the policy score to get the constrained policy score.
With the probability of feasibility computed, we can scale the policy, e.g. expected improvement (EI), score of each unseen point in the search space by the probability the point is feasible.
If the data point is likely to satisfy the constraints, then its EI score will be multiplied by a large number (a high probability of feasibility), thus keeping the EI score high.
If the data point is unlikely to satisfy the constraints, then its EI score will be multiplied by a small number (a small probability of feasibility), thus keeping the EI score small.
To implement inequality outcome constraints, acquisition functions that utilize Monte-Carlo (MC) sampling are used as this allows us to directly pass a list of constraint callables. These are any acquisition functions that inherit from SampleReducingMCAcqquisitionFunction.
Implementation
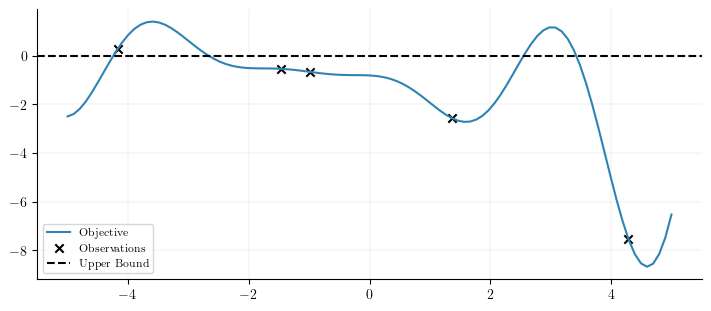
To implement inequality outcome constraints, only a list of constraint callables which map a Tensor of posterior samples of dimension sample_shape x batch-shape x q x m-dim to a sample_shape x batch-shape x q-dim Tensor. The associated constraints are considered satisfied if the output is less than zero. In the example below, we aim to minimize the Forrester function subject to the following constraint that \[f(x) < 0\]
Note: Since we are minimizing, the objective function is inverted, and thus the inequality is also inverted.
def objective_fn(x):return-((x +1) **2) * torch.sin(2* x +2) /5+1+ x /3
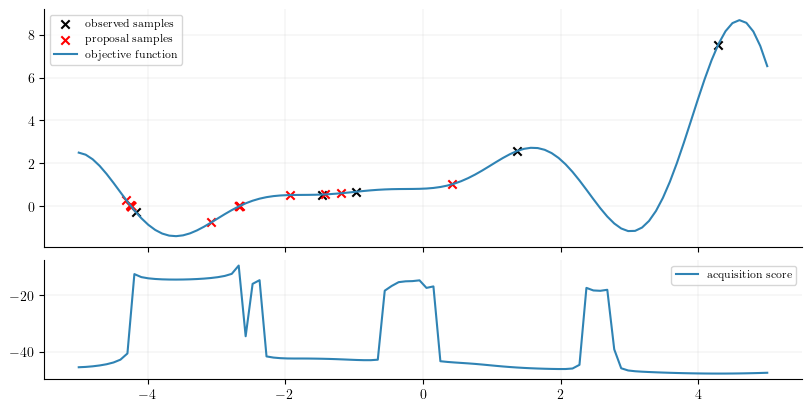
The Bayesian optimization loop below uses the qLogExpectedImprovement policy. To impose the desired inequality outcome constraint \(f(x) < 0\), a list of callables [lambda Z: Z.squeeze(-1) - upper] is passed to constraints. This callable subtracts the posterior samples \(Z\) by upper which is \(0.0\). If the result of this is less than zero, then the constraint is satisfied.
Note that \(Z\) here would be passing in all outcomes if a multi-task GP had been defined, so you want to index into \(Z\) appropriately and make separate callables for each outcome, e.g. constraints=[lambda Z: Z[..., constraint_outcome_idx]]. However, in this example, there is only one outcome, so we can just use Z.squeeze(-1) to select the correct (and only) outcome dimension.
The objective function has been flipped back to its original form to visually evaluate the optimization loop. Notice how the majority of the proposed points that minimize the objective function are near\(0\). Points that are below \(0\) happen due to the fact that we are using a probabilistic surrogate model to compute the probability of feasibility. The predictions of this model are not perfect, and thus, it is possible that the optimized policy score informs the next query to be a point below \(0.0\). Nonetheless, the minimizing points are found near \(-4.2\), \(-2.5\), and \(-1.5\).