As the business landscape embraces data-driven approaches for analysis and decision-making, there is a rapid surge in the volume of data requiring storage and processing. This surge has led to the growing popularity of OLAP database systems.
An OLAP system workload is characterized by long running, complex queries and reads on large portions of the database. In OLAP workloads, the database system is often analyzing and deriving new data from existing data collected on the OLTP side. An OLAP workload is in contrast to OLTP systems, where the workload is characterized by short running repetitive operations that operate on a single entity at a time.
This blog aims to provide an overview of the popular data storage representations and encoding schemes within OLTP and OLAP database systems. First, OLTP data storage will be discussed followed by OLAP systems.
OLTP
File storage
A DBMS stores a DB as files on disk (as long as the DB is not an in-memory DB). The DBMS storage manager is responsible for managing a DB’s files, e.g. keeping track of what has been read and written to pages as well as much free space is in these pages. It represents the files as a collection of pages.
Pages
The DBMS organizes the DB across one or more files in fixed-size blocks called pages. Pages can contain different kinds of data such as tuples, indexes, and log records. But most systems will not mix these types within pages. Additionally, some systems require that pages are self-contained, meaning that all the information needed to read each page is on the page itself.
Each page is given a unique identifier. Most DBMSs have an indirection layer that maps a page id to a file path and offset. The upper levels of the system will ask for a specific page number. Then, the storage manager will have to turn that page number into a file and an offset to find the page.
Most DBMSs use fixed-size pages to avoid the engineering overhead needed to support variable-sized pages. There are three concepts of pages within a DBMS: 1. Hardware page (usually 4KB) 2. OS page (4KB) 3. Database page (1-16KB)
Page storage architecture
Different DBMSs manage pages in files on disk in different ways. A few of the common organizations are: - Heap file organization - Tree file organization - Sequential/sorted organization (ISAM) - Hash organization ##### Heap files
A heap file is an unordered collection of pages where tuples are stored in random order. - Create/get/write/delete page - Must also support iterating over all pages
TODO: Diagram here…
It is easy to use if there is only one file. Need meta-data to keep track of what pages exist in multiple files and which ones have free space. The DBMS can locate a page on disk given a page id by using a linked list of pages or a page directory. - Linked list: Header page holds pointers to a list of free pages and a list of data pages. However, if the DBMS is looking for a specific page, it has to do a sequential scan on the data page list until it finds the page it is looking for. - Page directory: The DBMS maintains special pages that tracks the location of data pages in the database files.
Page layout
Every page contains a header of metadata about the page’s: - Page size - Checksum - DBMS version - Transaction visibility
There are two main approaches to laying out data in pages: (1) slotted-pages, and (2) log-structured.
Tuple oriented (slotted pages)
The most common layout is called slotted pages.
Slotted pages: Page maps slots to offsets - Most common approach in row-oriented DBMSs today - Header keeps track of the number of used slots, the offset of the starting location of the last used slot, and a slot array, which keeps track of the location of the start of each tuple - To add a tuple, the slot array will grow from the beginning to the end, and the data of the tuples will grow from end to beginning. The page is considered full when the slot array and the tuple data meet.
TODO: Diagram here…
Tuple layout
The DBMS assigns each logical tuple a unique identifier that represents its physical location in the DB - File id –> Page id –> Slot number
A tuple is essentially a sequence of bytes. It is the job of the DBMS to interpret those bytes into attributes (columns) and values. ##### Tuple header
Each tuple is prefixed with a header that contains meta-data about it - Visibility information for the DBMS’s concurrency control protocol (i.e., information about which transaction created/modified that tuple). - Bit Map for NULL values. - Note that the DBMS does not need to store meta-data about the schema of the database here.
Tuple data
Attributes are typically stored in the order that you specify them when you create the table. Most DBMSs do not allow a tuple to exceed the size of a page.
TODO: Diagram here…
Tuple identifier
Each tuple in the DB is assigned a unique identifier. Most commonly this is page_id + (offset or slot).
Denormalized tuple data
A DBMS can physically denormalize (e.g. pre-join) related tuples and store them together in the same page. - Potentially reduces the amount of I/O for common workload patterns. - Can make updates more expensive.
TODO: Diagram here…
Conclusion
Database is organized in pages. Different ways to track pages. Different ways to store pages. Different ways to store tuples.
OLAP
OLAP workloads typically require scanning large portions of a table(s) to analyze data. However, OLAP queries rarely select a single column, i.e. the projection and predicates often involve different columns.
SELECT product_id,
avg(price)
FROM sales
WHERE time > '2024-01-01'
GROUP BY product_id;The DBMS needs to store data in a columnar format for storage and execution benefits. Thus, a columnar scheme that still stores attributes separately but keeps the data for each tuple physically close to each other is desired.
PAX storage model
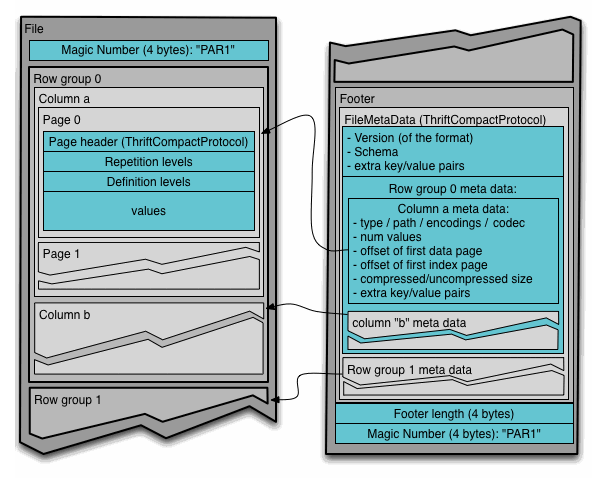
Partition attributes model (PAX) is a hybrid storage model that vertically partitions attributes within a DB page. - This is what Parquet and ORC use. - The goal is to get the benefit of faster processing on columnar storage while retaining the spatial locality benefits of row storage.
Horizontally partition data into row groups. Then, vertically partition their attributes into column chunks.
Global meta-data directory (a zone map) contains offsets to the file’s row groups. Each row group contains its own meta-data header about its contents. The meta-data directory is at the bottom (the footer) because these files are big and we don’t know what the metadata is going to be (min/max value) until we have processed all of the data. This also comes from the Hadoop world and the file is an append-only file, and we can’t make in-place updates. When we are done writing all of the rows groups of the file, we then close the file.
Zone maps, originally known as Small Materialized Aggregates (SMA), are a type of metadata used in database systems to improve query performance by enabling efficient data pruning. A zone map is essentially a pre-computed aggregate that summarizes the attribute values within a block of tuples. For each block, the zone map stores metadata such as the minimum (MIN), maximum (MAX), average (AVG), sum (SUM), and count (COUNT) of the values in that block. This metadata allows the database management system (DBMS) to quickly determine whether a block contains relevant data for a query without having to scan the entire block.
TODO: diagram…
File format decisions
There are a number of decisions when architecting a new file format for OLAP. Of which may include: - File meta-data - Format layout - Type system - Encoding schemes - Block comparison - Filters - Nested data
File meta-data
Files are self-contained to increase portability, i.e. they contain all the relevant information to interpret their contents without external data dependencies.
Each file maintains global meta-data (usually in the footer) about its contents - Table schema - Row group offsets - Tuple counts / zone counts
This is opposite to PostgreSQL because in PSQL you have a bunch of files that keep track of the catalog (schema, tables, types, etc.). Then you have pages for the actual data. In order for us to understand what is in our data pages, you need to go read the catalog.
Format layout
Most common formats like Apache Parquet and ORC use the PAX storage model that splits data row groups that contain one or more column chunks.
Type system
Defines the data types that the format supports. - Logical: Auxiliary types that map to physical types - Physical: low-level byte representation
Formats vary in the complexity of their type systems that determine how much upstream producer / consumers need to implement.
Encoding schemes
An encoding scheme specifies how the format stores the bytes for contiguous data (can apply multiple encoding schemes on top of each other to further improve compression). - Dictionary encoding (the most common) - Run-length encoding (RLE) - Bitpacking - Delta encoding - Frame-of-reference (FOR)
Dictionary compression
How we convert variable length data, e.g. Strings to fixed-length data that we can then compress.
Replace frequent values with smaller fixed-length codes and then maintain a mapping (dictionary) from the codes to the original values. - Codes could either be positions (using a hash table) or byte offsets into a dictionary. - Optionally sort values in the dictionary. - Further compress dictionary and encoded columns.
Format must handle when the number of distinct values in a column is too large. - Parquet: Max dict. size = 1MB - ORC: Pre-compute cardinality and disable if too large.
Block compression
Compress data using general-purpose algorithm. Scope of compression is only based on the data provided as input - LZO (1996) - LZ4 (2011) - Snappy (2011) - Zstd (2015)
Considerations: - Computational overhead - Compress vs. decompress speed - Data opaqueness
Opaque compression schemes - if you run something through Snappy or Zstd the DB system does not know what those bytes mean and you cannot go and jump to arbitrary offsets to find the data you are looking for. You need to decompress the whole block.
This made sense back in the 2000s and 2010s because the main bottleneck was disk and network, so we were willing to pay the CPU costs. But know the CPU is actually one of the slower components. ##### Filters
What is the difference between a filter and an index?—An index tells you where data is, a filter tells you if something does exist. ###### Zone maps
Maintain min/max values per column at the file-level and row group-level.
More effective if values are clustered.
Parquet and ORC store zone maps in the header of each row group. ###### Bloom filters
A probabilistic data-structure (can get false positives but never false negatives).
Track the existence of values for each column in a row group. #### Nested data
Real-world data sets often contain semi-structured objects, e.g. JSON, Protobufs.
A file format will want to encode the contents of these objects as if they were regular columns.
Two approaches: 1. Record shredding 2. Length + presence encoding
Shredding
Instead of storing the semi-structured data as a “blob” in a column because every single time you need to parse the blob, you need to run JSON functions to extract the structure from it.
We are going to split it up so that every level in the path is treated as a separate column. Now we can rip through a column for a given field in the JSON, does it have this attribute with a certain value.
There is always a schema because it doesn’t make sense to have random applications inserting random documents into a table.
TODO: insert diagram
For each path, store it as a separate column and record how many steps deep we are into a given document for that hierarchy. Essentially, we are storing paths as separate columns with additional meta-data about paths.